While working for a particular client project, I was asked to review an existing long running Turbo Integrator (TI) process and find out ways to optimise its processing time, without compromising on the business functionality.
Synopsis:
A process was created to adjust the amount between cost centres and products based on defined From and To mapping in a mapping cube.
A simple example could be, amount from one cost centre be adjusted to multiple centres within its division or a consolidation of centre within a division mapped to same consolidation but for a different product.
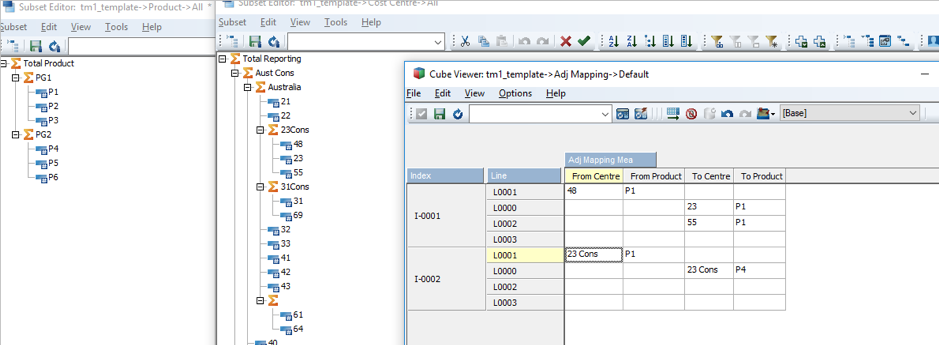
To achieve this, the process was divided into two. A main process, that loops all From line Items and creates the source view in Prolog and a sub process within the same loop, which the main process then calls for each From line item, passing the view created in Prolog as a parameter to the sub process.
The sub process consumes that view as a source and loops through all To line items in Data Tab to adjust the amount from From Centres to To Centres.
Analysis:
Upon investigation it was noted that while the view was created for all From line Items and passed as source for sub TI to process the adjustments, not all source views had data in it (in fact majority didn’t) thereby resulting in sub process adjusting “0” amount to To Centres leading to unnecessary processing.
In order to resolve this inefficiency, I had initially thought of performing a CellGetN on From parameters before executing the sub process to ensure we only call it if the value returned is not 0. However, there was a minor issue with this approach; if a From parameter is defined as a consolidation, the data at that level was netting off due to credit and debit entries and as a result the sub process basis the condition was not getting executed; although in theory it should have as there is data available in child centres.
Solution:
I decided to use ConsolidatedCount function in conjuction with CellGetN to address the limitation; As opposed to returning the aggregated value with CellGetN, this function counts the value in a consolidation and hence as long as the weight of the elements were not set to 0 (which in my case holds true) this will always return either 0 (when there is no data) or a positive number that I can use as a condition before calling the sub process.
To summarise, while this would have saved only few seconds for skipping an execution of a sub process (as the sub process still captures the TI stats in epilog), given there were thousands of line items that returned 0, it gained considerable efficiency in TI processing times. Not to mention the effective gains from optimum usage of system resources that otherwise were getting unnecessarily utilised.
For more Information:
To check on your existing Planning Analytics (TM1) entitlements and understand “how to”, reach out to us at info@octanesolutions.com.au for further assistance.
Get a free one-hour consultation on us.
Octane Software Solutions Pty Ltd is an IBM Registered Business Partner specializing in Corporate Performance Management and Business Intelligence. We provide our clients advice on best practices and help scale up applications to optimise their return on investment. Our key services include Consulting, Delivery, Support and Training.
Octane has its head office in Sydney, Australia as well as offices in Canberra, Bangalore, Gurgaon, Mumbai, and Hyderabad.
To know more about us visit, OctaneSoftwareSolutions.


Leave a comment