Often times, when we as a developer are loading the data from a particular source and intend to create a view to debug the data for analysis and troubleshooting, typically we do it by creating the view and subsets and assigning the subsets to the view in Prolog tab.

The elements from the source are then added to the subset in data tab by using SubsetElementInsert function. This will work seamlessly as long as there is only one record for one element in the source.
As soon as the TI encounters multiple records of each element, it starts to add that element again in the subset resulting in duplicate elements being added to the subset. The end result of this will be a view with too many duplicate entries making it very confusing and clunky to derive any insights out of it.
Let’s illustrate that proposition with sample data using csv file as a source for two scenarios discussed above:
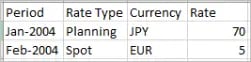
- No duplicate records in the source:
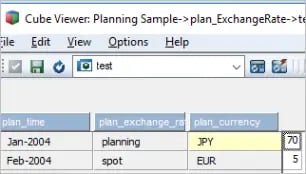
In the above sample data, Period, Rate Type and Currency are dimensions and Rate is the data to be loaded. As you can observe, there are no duplicate elements identified in the sample data. The output of the view based on the above data and using SubsetElementInsert to add elements to the subset is as below.
- Duplicate records in the source:
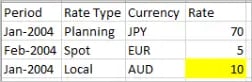
In the latest set of sample data, I’ve added a new record highlighted in yellow. Notice that I’ve only added existing period (Jan-2004) in new record while maintaining the other elements unique.
The out of the view with this set of data is presented below.
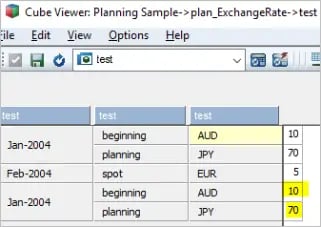
Bug:
As per the sample data, there must only be an additional intersection that should have been added to the view, however, upon checking, we can easily notice that there are now 5 records that are appearing in the view. The two duplicate records highlighted in yellow is due to Jan-2004 being added twice using SubsetElementInsert function.
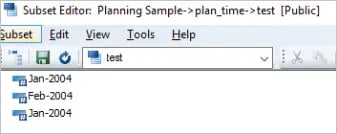
For the sake of brevity, a very simplistic scenario was used with only one element appearing twice and for only one dimension, however in live environment you will have significant number of such instances with various permutations and combinations thereby increasing the number of duplicate records to manifold.
De-bug:
As a part of TM1 10.2.2 FP6, IBM has introduced a new TI function – SubsetGetElementIndex. Related documentation for it can be found here.
The function returns the index of first occurrence of the specified element from the subset of a dimension.
Let’s now leverage this function to address the issue at hand.
We know that Plan_time is the dimension where we are encountering the elements twice in the subset. We will use the new TI function in conjunction with SubsetElementInsert function to limit adding more than once instance of Jan-2004 to the subset. To do that, we will enclose that function within the IF block.
IF (SubsetElementGetIndex (sDim, sSubsetName, vPeriod, 1) = 0); SubsetElementInsert (sDim, sSubsetName, vPeriod, 1); ENDIF;
Where
sDim = dimension name (Plan_time)
sSubsetName = subset name (test)
vPeriod = Period variable from source
Conclusion:
By leveraging the new SubsetElementGetIndex function in combination with SubsetElementInsert function, we are successfully able to effectively create a clean concise view with unique instances of the elements for analysis and debugging. Stay tuned for more tips and tricks and other quick hacks in TM1 and until then happy debugging!


Leave a comment