Thank you if you have come back for more! Hope our last blog Unraveling TM1 : Lesser Known Facets – Part A was meaningful. In this part we will unearth & explore few more of these lesser known gems.
As always, if you like what we do and want to associate; subscribe to our Blogs at http://blog.octanesolutions.com.au
Function TM1RPTROW
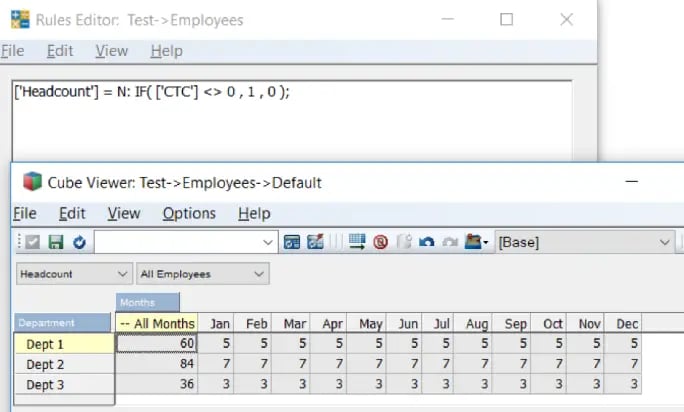
We know TM1RPTROW is a salient function when building demand and rolling forecasts in Planning and Budgeting models
Although everyone is aware of the fact that parameters like Dimension Subset, MDX Expressions are a part of TM1RPTROW, developers tend to assume the following features are either hard to achieve or are time consuming.
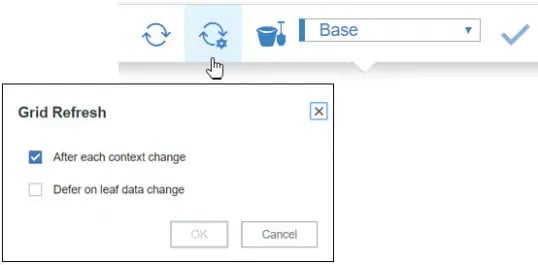
TIP 4. Search Functionality on the elements of TM1RPTROW
Subset elements can be filtered by wildcard search in Subset editor; we all now this. Similar approach has been used to look for an element in websheets.
As an alternative to subsets in TM1RPTROW, let’s look into another parameter which serves the purpose - MDX
Syntax: TM1RptRow(ReportView, Dimension, Subset, SubsetElements, Alias, ExpandAbove,MDXStatement, Indentations, ConsolidationDrilling)
.webp?width=684&height=273&name=S1(1).webp)
As an illustration, consider a TM1 Websheet created to understand how it could be done.
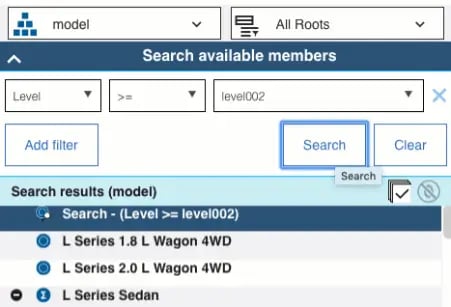
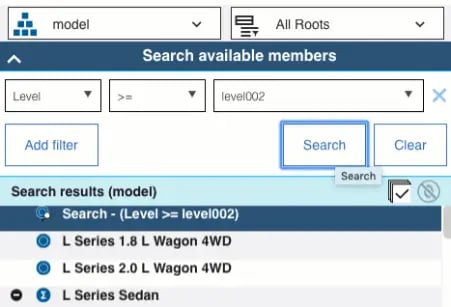
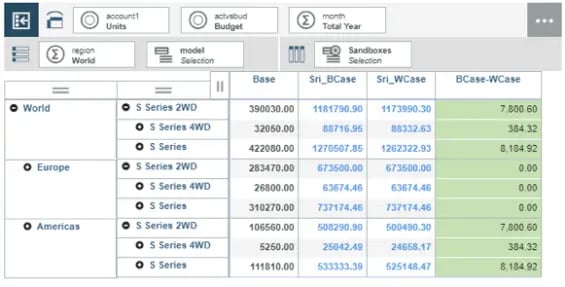
As shown in the screenshot below, a search option has been provided with for a model from the view.
Create the MDX expression which is to be referred in a cell as illustrated below
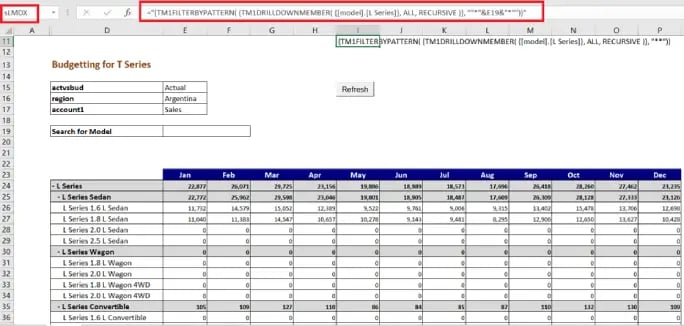
In the screen shot, MDX (Cell I11) is getting filtered based on the data provided in cell E19.
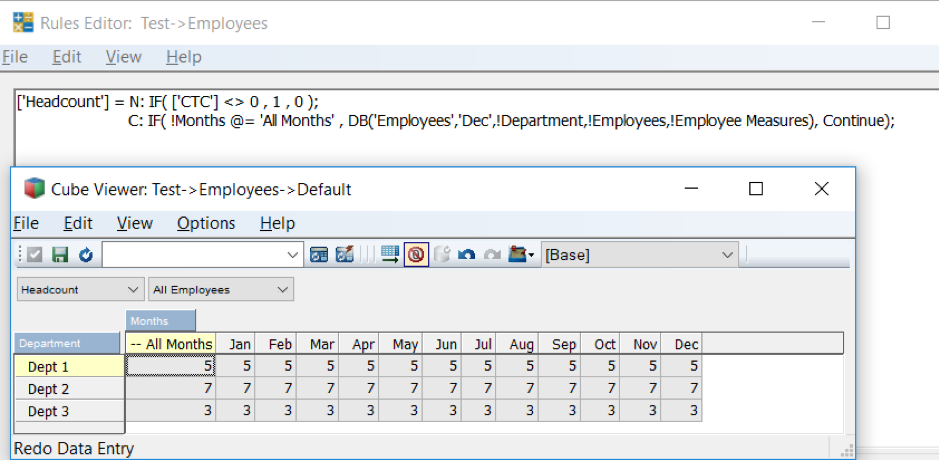
This is when the MDX parameter of TM1RPTROW must be updated to refer to the Cell I17(named as sLMDX) as shown in screenshot below.

It can be seen that MDX Parameter is updated to refer the MDX expression only if search cell has some value and not when null (in the case as TM1RPTROW functionality Subset will take precedence)
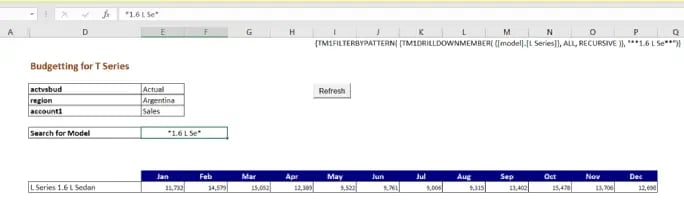
Resulting a view as per the search expression; Provide a wildcard expression (which is supported in TM1) and refresh the sheet.
View will be refreshed with data for only the searched elements as shown below. Thereby delivering the purpose.
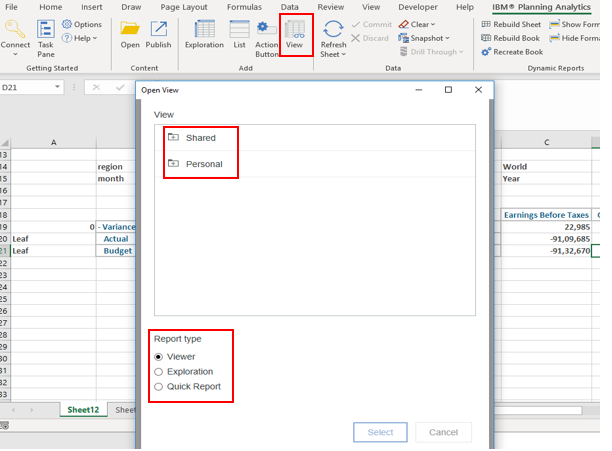
TIP 5. Switching between two different views in TM1 Web
Though not a requisite to have to switch between 2 different views, there comes times and a business need which may require you to deliver different views.
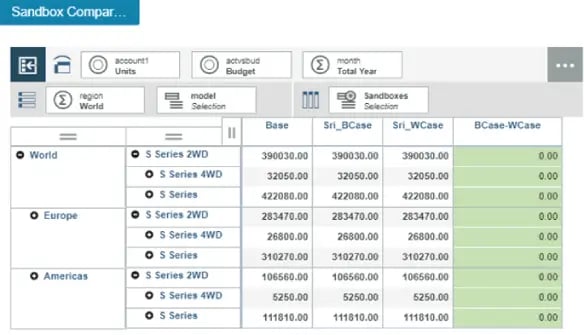
Consider an Example of standard IBM model Salescube in Sdata Instance.
In Model Dimension of SalesCube, we have model elements S Series, L Series and T Series. User Case: ‘S Series’ and ‘T Series’ model (in this case being car models) need to be forecasted/Budgeted for future years based on the actuals of L Series.
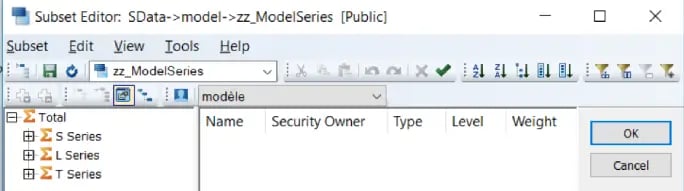
To accomplish this, the Web screen should show ‘L Series’ as selected actuals and ‘T Series’, ‘S series’ for Forecast/Budget version.
For illustration purpose, consider the TM1 Websheet below…
As we know by now, TM1RPTROW has a parameter to provide Dimension Subset.
We will create 3 subsets which has L Series elements, T-Series & S-Series elements respectively
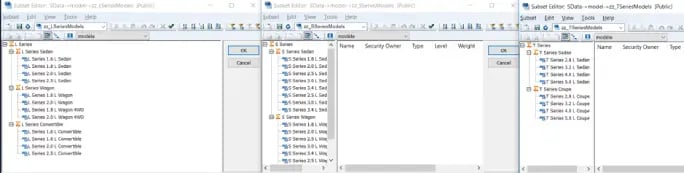
Definitely not as complicated as it may sound, When actual is selected:
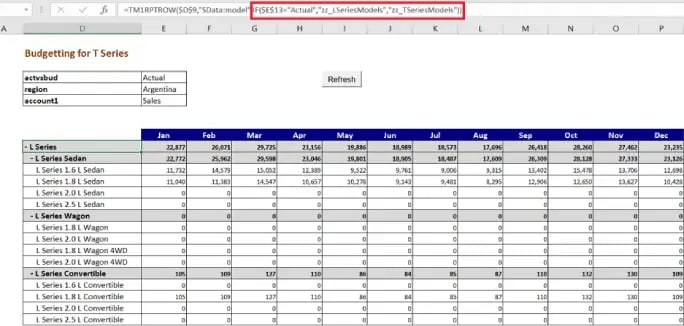
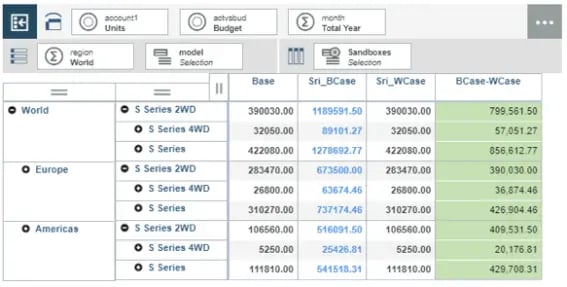
From the screenshot, it is clear that when “actvsbud” is changed from Actual to any other Version, the view of a websheet will change (as specified in TM1RPTROW) once refreshed. Developers can use Nested IF, if the requirement is to have different view sets for each selection in the dimension.
Refreshing the websheet results in (refer image below);
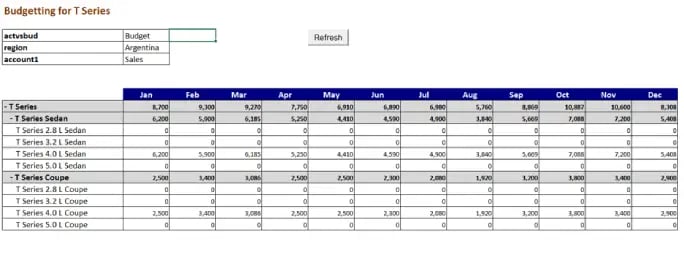
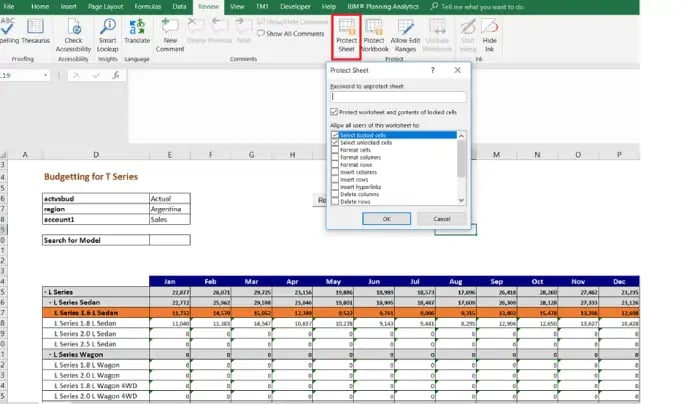
TIP 6. Locking rows to restrict user entry
Think SECURITY; there would be scenarios when users are provided with view access only into TM1 Web applications.
While security is good and essential, there would be times when the underlying cube has huge volumes of data and applying cell security may result in performance issues.
While formatting (locking the cells/row of a particular measure) in excel is an option, formatting an area in TM1 active form can be used extensively to avoid cell security.
Consider an example (refer fig below), the need is 1.6 Series to be non-editable.
Using excel ‘IsNumber’ and ‘search’ function look for 1.6 in the TM1RPTROW elements (as shown in the below screenshot). Name the row as L to setup formatting in format area of active form.
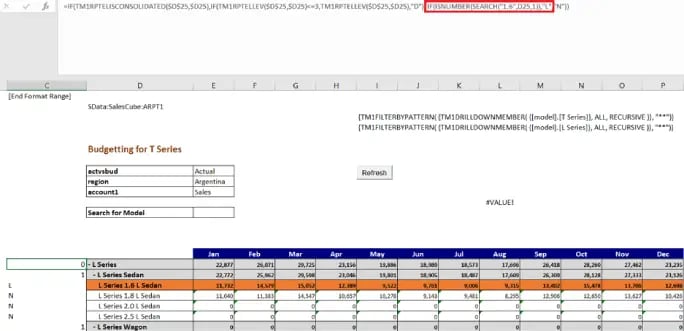
Insert a row in the format area and name the row as L as shown below.

Format colour as user’s requirement and lock the cells as shown below.
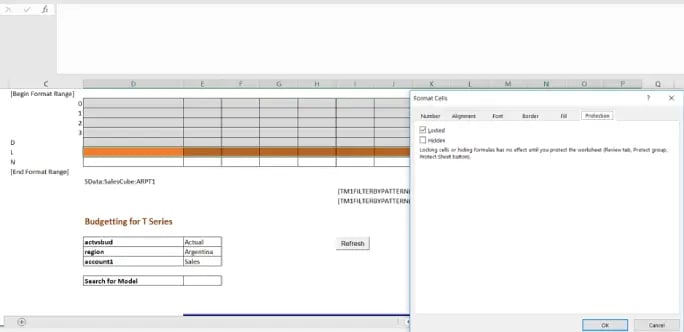
Hide rows and columns within active forms which are not meant for users, protect the sheet in review tab as shown below.
Hope you would have enjoyed reading this blog as much as I had testing these cool features; so until next time, keep planning on IBM Planning Analytics!
You may also like reading:
“ What is IBM Planning Analytics Local ”
“IBM TM1 10.2 vs IBM Planning Analytics”
“All you need to know about Planning Analytics 2.0.5”
“Little known TM1 Feature - Ad hoc Consolidations”
“IBM PA Workspace Installation & Benefits for Windows 2016”
“101 Guide to Blockchain”
“TI Optimisation – An Epilogue”
To Subscribe, visit http://blog.octanesolutions.com.au
For more Information: To check on your existing Planning Analytics (TM1) entitlements and understand “how to”, reach out to us at info@octanesolutions.com.au
Octane Software Solutions is an IBM Registered Business Partner specializing in Corporate Performance Management and Business Intelligence. We provide our clients advice on best practices and help scale up applications to optimise their return on investment. Our key services include Consulting, Delivery, Support and Training.
Octane has its head office in Sydney, Australia as well as offices in Canberra, Bangalore, Gurgaon, Mumbai, and Hyderabad.
To know more about us visit, OctaneSoftwareSolutions.







-1.png?width=457&height=90&name=image%20(2)-1.png)











Leave a comment